Replication Tracker
Tool to crowdsource the tracking of (un)published replications in psychology and beyond (alpha version; beta version code).
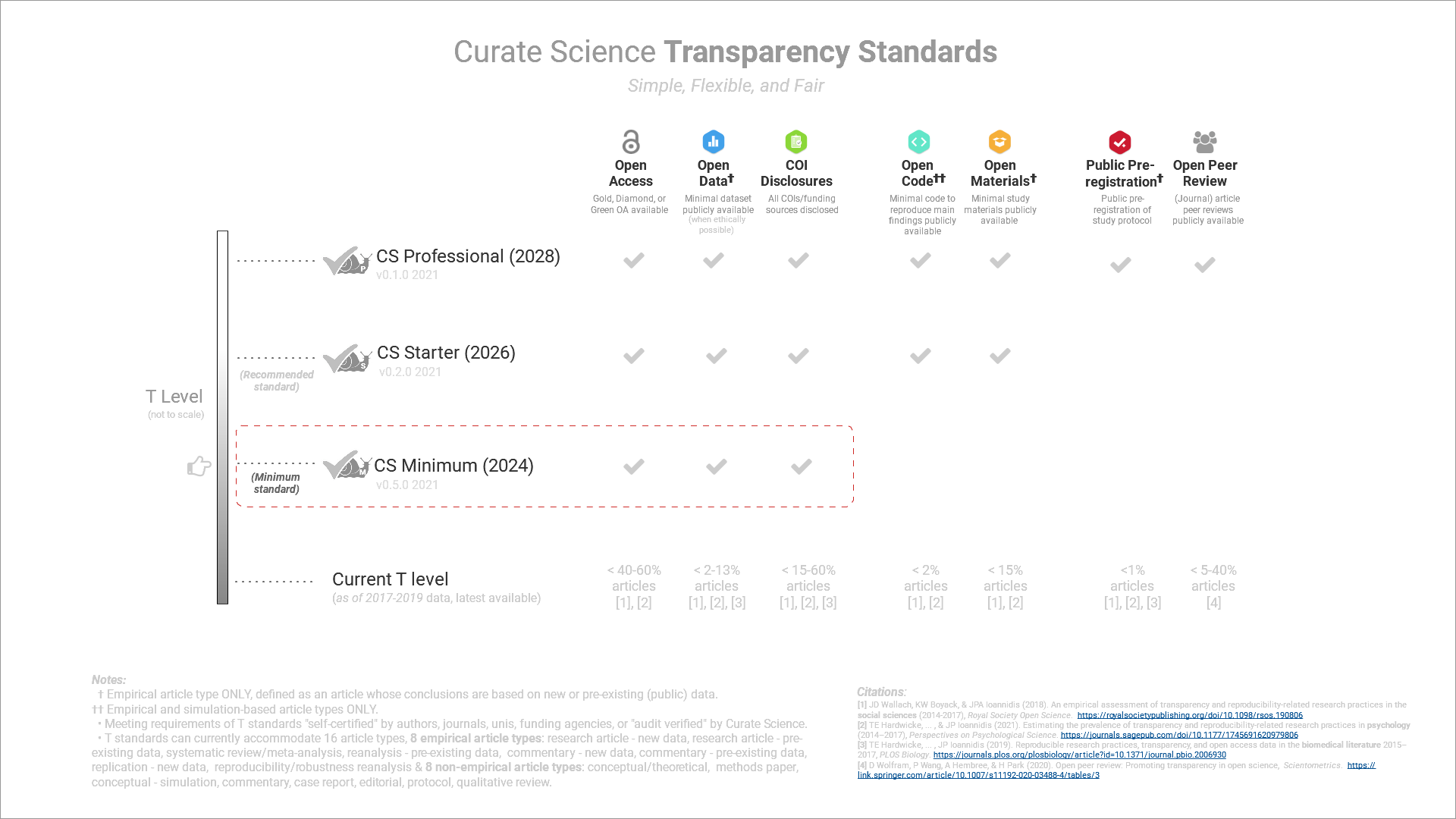
Transparency Standards
Transparency standards that can be flexibly used across all areas of science.
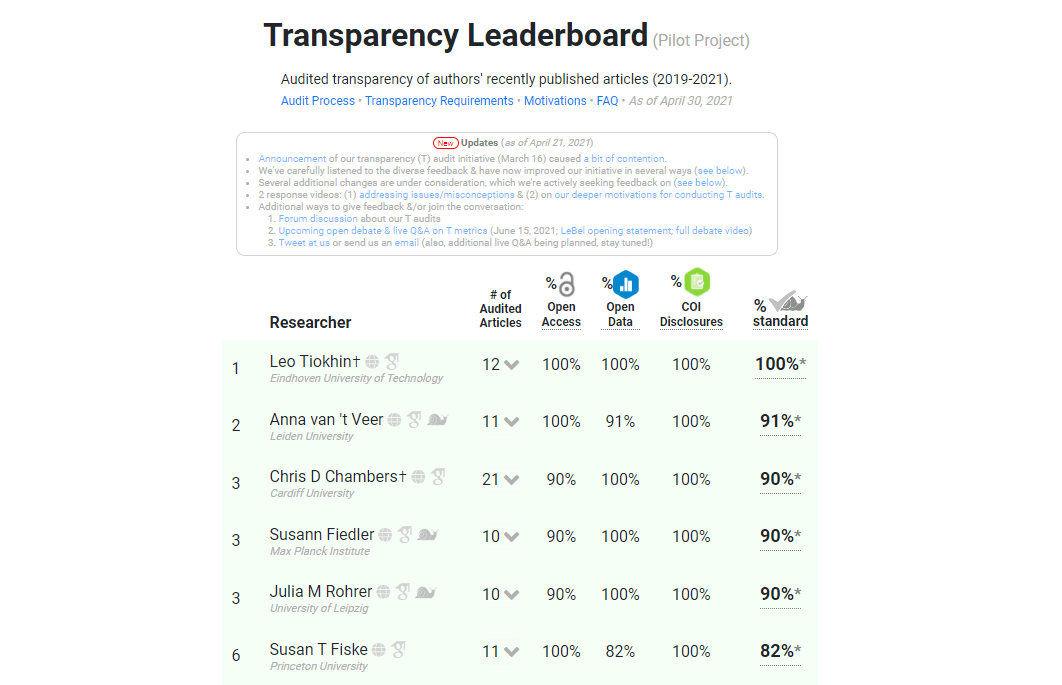
Transparency Audits
Conducted the world's first transparency audits in science (live debate about transparency audits more generally).